这五个字,能优化你80%的程序性能问题

 分类:
分类: 已被围观
已被围观 本篇关注程序性能优化。聚焦这个主题,本是偶然。始于玩笑,终于本心。本想找点高大上的让人直呼牛逼的东西,奈何能力有限,只能给大家一些既便宜、又好用、还简单的普通东西了,不知道你们会不会喜欢。
分为五个主题,分别是『池』『序』『分』『减』『并』:

池化,降低可重用对象的创建和回收代价。
不知道你们发现没有,无论是电影还是游戏中,主角总是孤胆单英雄,最多三五成群。但Boss不一样,Boss手一挥,必须有一群小怪一拥而上,毕竟帮主角刷点经验也是好的。
小怪的特点是:数量多,容易死,循环用。电影不可能请太多的群演,因此我们经常能发现一人分饰多角的超级龙套。而游戏里,也不可能每一个小怪都完全不一样,因为创建它们还挺消耗时间和内存的。哈哈,现在你知道了,你正在打的小怪很可能与刚刚死前掉金币的那只是同一只。
代码中,如果某些对象有重用的价值,并且创建的时候会消耗大量的CPU或IO资源。那么在出现性能瓶颈的时候,一个合理的优化方向就是池化。刚刚例子中,对游戏中小怪进行池化,通常称为对象池,类似的还有线程池、连接池等。
灰太狼:我一定会回来的~
顺序读写,减少随机IO,减少cache miss。
『内存顺序读写的性能要远好于随机读写』,『磁盘顺序读写的性能要远好于随机读写』。类似的话我相信很多程序员都似曾相识,然而,我同样相信很多程序员在写代码的时候从来没有认真考虑过这件事件。

当年做游戏的时候,我见过很多人使用hash表存储场景中的各类对象:花鸟鱼虫、白云苍狗,并每帧遍历hash表以确定位置或攻击信息。我建议他们改成遍历有序表的快照(MVCC了解一下),其中一个原因是可以提高遍历性能,而另一个更重要的原因是可以在遍历的过程中修改表结构(插入删除对象)。
有序表一种基于有序数组的字典结构,C#中有一个名为SortList的标准库实现
多年以来,CPU一直是计算机中跑得最快的部件,也因此被惯出来一个多吃多占的毛病。无论是读内存还是读磁盘,从来不讲究按需分配,而是大块大块的拿数据。当把一大块连续的数据拿到手里的时候,CPU自己也知道一次肯定吞不下,但总觉得多吞几次就好了。
但这个特点其实是需要程序员去配合的,如果代码使用连续内存的数据结构,比如array,那在遍历的时候就相当于投其所好;而如果代码使用hash表,则遍历的时候cache miss的可能性就大大增加。
鉴于java在服务器领域的成功,有些公司使用java开发游戏服务器,我建议他们换一种语言。原因是游戏服务器很可能需要处理大量跟点、向量等三维空间相关的运算,而在java中,默认一切都是对象。于是在一个Vertex(顶点)数组中,看似连续的Vertex对象在物理内存中实际上是离散的,这样的遍历效果就会差很多。而对C++, Golang,甚至C#这类语言来说,它们都支持struct。当把Vertex定义为struct的时候,一个Vertex数组的占用的内存就是连续的,遍历效果会比java好很多。
在后端的技术栈中,kafka绝对是一个非常另类的存在。擅长kafka的人,觉得无它不欢,而不了解它的人,则觉得可有可无。关于kafka为什么这么快的讨论有很多,其中有一个绕不过的原因是:kafka会顺序读写磁盘。我们通常认为磁盘的读写性能远低于内存,但实际上,在关闭fsync的前提下,SSD固态硬盘的顺序读写速度与内存的随机读写速度是相当的,大概都是1 GiB/s,而如果是随机读取,则SSD固态硬盘SSD的Seek速度会直降到70MiB/s,速度下降到1/15。
鸿蒙伊始,民智不开。为教化万民,神器计算机降世。下凡走得急,零件没凑齐。计算机天生残疾,CPU与其它IO部件速度差异过大。为平衡这种速度差异,人间有智者布局各方,分字诀应劫而生,它们是分批、分帧、分页、分时、分片、分区、分库、分表、分离。
1. 分批≈缓存+缓冲
在系统设计之初,每次修改对应一次IO可能是最简单、最直接的设计,不过随着系统流量变大,IO可能会很快成为系统瓶颈。相比于内存操作来说,磁盘IO吞吐小,网络IO延迟大。为了减少IO与内存之间的速度差异,争取每次IO都物尽其用才是上上之选。将多次IO合并为一次,减少磁盘IO(特别是fsync)的次数和网络IO的round-trip次数。
所谓读优化靠缓存,写优化靠缓冲,而分批≈缓存+缓冲。往小了说,缓存就是一块用于读内存,缓冲就是一块用于写的内存。往大了说,缓存就是Redis,缓冲就是Kafka。这些都是在微服务体系中司空见惯的招数,不用我多说。
分批优化化身千万,可谓无孔不入,甚至多数流行的数据中间件都提供了批量IO操作的API:
- MySQL的insert语句支持在values中一次插入多行数据。
- Redis的Pipeline操作可以批量执行多个操作。
- ElasticSearch有专门的_bulk api支持在单次调用中索引或删除多条数据。
- Kafka更是把分批操作贯彻到了极致:它根本就不提供发送单条消息的功能,使用send()发送的单条消息其实会被Kafka偷偷在内存里攒起来,是的你被骗了。
- 包括MySQL, Redis在内的各类数据中间件,跟WAL日志落盘时机相关的配置中,一定有一条是只写Page Cache,然后后台线程定期刷盘的策略。(注:严格说来,Redis那个不能叫WAL,因为它是写后日志。)
- 在游戏引擎中,把顶点数据提交的显卡的Draw Call也都是合并批次的,否则会卡死你。
分批的缺点是在数据一致性差,无论是缓存还是缓冲都存在同样的问题。缓存的话,如果不存在严格的一致保障手段,往往只建议展示用,不作为数据修改依据。参考文章《缓存就像showgirl,看看就行了》。而缓冲在内存的这段时间内,如果进程崩溃了,会丢失部分数据。因此在选择分批优化的时候,架构师需要仔细斟酌数据一致性问题,比如是否可以接受偶尔丢失数据,或者是否需要在数据输入端提供重试策略。
但不管如何,分批都可能是最重要的IO优化手段:它逻辑简单,不涉及多线程并发,对数据结构没有特殊的要求,系统改造成本低。可以说,无论何时遇到IO性能瓶颈,分批改造都应该是顺位第一的候选方案。
2. 分帧、分页、分时
1)分帧,是专用于单线程+阻塞IO的平滑技术
很多时候,由于受框架限制(比如游戏或网页渲染),我们不得不在单一线程中同时处理用户逻辑与IO操作,这时如果IO消耗时间过长,就会阻塞用户逻辑代码,从而让用户感觉到卡顿现象。
Redis由于其单线程特性,很多耗时比较长的操作也需要分摊到多帧执行。比如hash表的rehash操作,当表的键值对过多时,rehash会产生的庞大的计算量,如果一次性完成可能会导致server对外暂停服务。Redis选择将rehash分摊到多次执行,称为渐进式rehash。
另外,对于比较大的hash表,hgetall一次性获取所有数据可能会卡死server进程甚至导致宕机,建议采用hscan来分次获取hash表中的数据。Redis中像这类支持迭代式扫描的命令有四个,分别是:scan, sscan, hscan和zscan。
2)分页可以看作是一种另类的分帧操作:
在运营类项目中,由于后台数据庞大,很多时候无法在单一网页中显示,通过分页显示,可以避免一次性数据获取带来的DB加载压力和网络传输压力。
3)分时复用指多对象轮流使用同一个硬件的技术,多见于跟硬件打交道的底层软件。
比如,分时操作系统:一种采用时间片轮转的方式同时为几个甚至几百个用户服务的操作系统;分时复用网络:指采用同一物理连接的不同时段来传输不同的信号,以达到多路传输目的的网络基础设施。
但有一种分时复用技术,虽然它的名字里没有分时二字,却与后端开发息息相关,那就是IO多路复用(洋名:Reactor):单线程同时监听多个文件句柄,哪个句柄就绪,就通知应用线程读写哪个句柄的技术。
3. 分片、分区、分库、分表
随着77年恢复高考,这些年近视的年轻人越来越多了,于是人们越发的无法区分那些换个马夹儿就重新出来混的二货们。就像洗发水,猛一看飘柔、海飞丝、潘婷百花齐放,仔细一看,全特么是宝洁的。没错,这么土味的名字,竟然不是国货,害我自以为爱了这么多年的国。
分片、分区、分库、分表也一样,名字挺花,疗效一样,都是为了突破单体性能限制的水平扩展的方案,洋名字:scale out。因为方案类似,大家遇到的问题自然也是相同的。它们首先要搞定的就是路由问题,也就是把数据拆分之后,某个key储存到哪个分片/区/库/表的问题。路由方案可简单分为两类:
一种是非确定性路由,即相同的key多次路由可以映射到的不同的计算单元,常见方案有:轮询、随机。非确定性路由多用于无状态节点间的任务分配,比如nginx把请求随机分配到无状态的微服务节点上。
另一种是确定性路由,即相同的key多次路由必须映射到的相同的存储单元,常见方案为:区间,Hash,配置表。确定性路由多用于有状态节点间的任务分配,比如Kafka按user_id把来自同一用户的请求映射到同一个存储分区。
以MySQL为例,它支持四种分区类型,分别是Range, List, Hash, Key。因为跟存储密切相关,它们全是确定性路由算法,其中Range对应区间,List是配置表,Hash与Key则都是Hash类型。
除了应用于多机水平扩展,在单机内存中分片方案也有应用。比如JDK1.8之前,ConcurrentHashMap通过将整个Map划分成N(默认16个)个Segment,而每个Segment各自持有独立的锁,从而从整体上减少并发冲突。
4. 分离
分离式设计是一种架构模式,通过把单元功能单一化、纯粹化、专业化,可以降低开发和维护成本,同时提高功能单元的可复用性,这在设计模式中我们通常称之为单一职责。目前,常见的分离式架构设计有读写分离、存算分离。
读写分离在国人的文章中常用于指代MySQL写走主库,而读走从库,这有些狭义了。广义上读写分离的重点是:读路径不关心写,写路径不关心读,两者均关注于自己的功能实现,而毋需为对方的作出任何牺牲或让步。更多的细节我在文章《23.kafka心中的事件溯源》中有更详细的描述,感兴趣的读者可以点击查看。
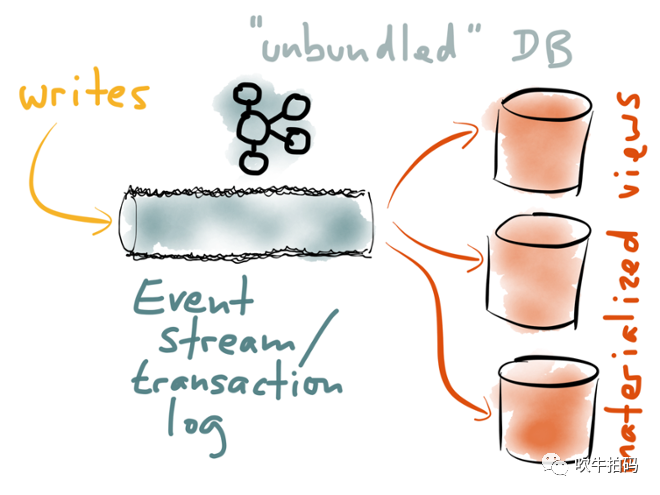
这里我想强调的是,读写分离是分离式DB(Unbunding Databases)的雏形。我们应该认识到,不存在一种单一的数据模型可以满足所有的访问模式。MySQL在线业务、Redis加速查询、ES全文索引、DW离线分析,每一种衍生数据系统都有各自不可替代作用。
如上图所示,通过统一写端,派生读端,可以形成一种遵循unix传统的架构模型:单一任务做好单一事情,内部通过低级API(pipe)通信,外部通过高级语言(shell)组合。在分离式DB架构中,目前看来最合适的,能起到粘接剂作用的是Event Stream(Event Log)。期望未来有那么一天,我们能像在shell中写ps | grep java一样,写出mysql | elasticsearch这样的代码,届时就是分离式DB摘取王之桂冠的荣耀时刻。
如果说读写分离是拆功能,那么存算分离就是拆资源:把计算资源(CPU、内存)和存储资源(磁盘)拆分开来。早期的云DB,其实是把单体DB搬到云上。人们很快发现云DB与单机DB的不同之处:一是随着企业数字化转型的深入,数量总量飙升,单机存储捉襟见肘;二是在应对双十一这类突发性流量时,计算峰值波动很大,这使得云DB对弹性伸缩能力要求极高。问题一可以通过分库分表这类trick的方式缓解,但问题二对原有单体DB『存算一体』的架构提出了挑战。于是,存算分离的架构应运而生,也就是云原生数据库架构。

存算分离听起来很云端,似乎跟我们平时的工作关系很小。但其实有一类架构它就在我们身边,只是我们可能没有意识到它也是存算分离架构,那就是微服务架构。计算节点无状态,存储节点无计算;计算节点横向扩展,存储节点纵向扩展。
就像Duck Test讲的:如果它看起来像鸭子、游泳像鸭子、叫声像鸭子,那么它可能就是只鸭子。
很多时候我们都讲不要过早优化,因为多数业务的初期,数据量都很少,任何设计都不太可能出现性能问题。反而业务上线后,由于进展不符合预期,导致调整业务逻辑的可能性更大。因此,怎么简单怎么来才是最优选择,更快的实现业务比业务跑得更快优先级更高。再者,你难道不觉得,就凭咱们拿的那万儿八千的工资,在非常合理的情况下,就不应该写出支撑千万并发的系统,嘛?
万一哪天系统开始出现性能瓶颈呢?该怎么办?恭喜哈,这是好事,说明公司赚钱了,更重要是通过你的系统赚钱了。首先,你要做的第一件事就是跟老板要经费,经费到手,万事不愁。然后,想办法把系统恢复到数据量小的时候,这不就又顺理成章的撑住了嘛?接着,经费没地方花了不是?总得找个地方放啊,我私下认为你的钱包就是一个不错的地方。
怎么把数据量再次变小呢?劝退用户是一个办法,但我估计老板可能太不乐意。
一个更可行的选择是优化数据结构和算法。比如给DB建索引就是一个办法,同样的查询,同样是千万级的数据,有索引和无索引的查询速度千差万别,因为索引会极大减少扫描的数据行数。
另一个选择是裁剪数据。就像Java的GC会定期清理垃圾一样,如果你发现DB里的数据大部分都是过期无效的,或者是基本上不会再查询到的数据,把过期数据归档,减少线上数据集的尺寸会是一个非常好的选择。该操作系统改造成本极低,对线上业务无影响,对数据后台则可以看心情逐步改造。所有相关人员都压力不大,但效果却是线上系统从此秒开,绝对骚得一批。其实前面提到的分片、分区、分库、分表,也都是在变相减小单位处理单元上的数据量,只不过它们改造成本高,实施难度大。特别是,在决定采用分表之前,应慎重考虑归档是不是一个更合理的选择。
当年做手游,发现游戏在4k屏的手机上运行极慢,手机的GPU根本带不动,尝试了各种优化手段都不好使。谁曾想,最终解决问题的,竟然是降低游戏的输出分辨率。
算法上缩,物理上减,现在连国家不开始提倡65岁退休了,我们的老系统也一定能才坚持几年。
终于到了并发,一个大部分人都觉得应该有用,同时大部分人觉得用起来发怵的优化手段。
如果说前面的『池』、『序』、『分』、『减』这几条顶多算工程技巧,凭着我们聪明的大脑&反复思考就有可能搞清楚的话,『并发』这一条就是一个学术问题。换句话说,即使经过几年的系统学习,也很少有人敢拍胸脯说自己的并发代码无 bug。
并发真有这么难么?从编程语言的角度看,并发不就是多线程和死锁么?贤者大神们的文章已经解释得很清楚了,像《不环保的死锁:破解死锁,我们一般从下三路入手》、《线程安全,唯快不破》,只要规避掉死锁的几个必要条件,还不是怎么顺手怎么写?而且,运气好的话还可以无锁解决并发问题,不但准,而且快。
然而真相远不是这么简单。我们知道DB是解决数据安全和数据一致性问题的集大成者,我们尝试从DB的角度来观察一下。DB事务有ACID四个属性,其中I是指隔离性Isolation,而它的研究核心就是并发问题。
毛爷爷说事务物是运动发展的,我觉得他说的是对的。两年之前还没有新冠肺炎呢,今天它已经像吃饭喝水一样融入到了我们每个人的生活当中。在早期的ANSI SQL92标准中,涉及到的并发异象只有4种,然而发展到今天,常见的并发异象已经有7种之多,它们分别是:脏读、脏写、读倾斜(不可重复读)、写倾斜,不可重复读、幻读、更新丢失。每一种并发异象都有不同的原因,以及不同的解决方案,而这还不是全部。其实我很想稍微给大家科普一下这些异象相关的内容,但是我发现细节实在太多了。我盲猜后端的知识体系中,可能有一半都跟并发有关。
没人否定当年敲定SQL92标准的应该算DB专家吧?连当前ANSI的专家都没能完全搞清楚事情,谁敢告诉我他轻松就能搞定?
所谓单机并发榨硬件,多机并发扩上限(scale out)。当单线程服务遭遇性能瓶颈,同时相应的机器硬件还有富余的时候,进行多线程改造从而充分压榨硬件性能可能会是一个比较好的选择。相应的,当单机性能已经无法满足服务需要的时候,就需要进行分布式改造,通过水平扩容的方式提升整体服务能力。这两种思路,对应到『分』字诀中,恰好是分表与分库的区别:如果只是数据量上去了,CPU和内存压力都不大,那就分表再压榨一下;反之,如果流量大增,单机负载已经抗不住了,就可以考虑选择分库。
『并』字诀好使,但并不好掌握。引入并发会极大增大代码复杂度,提高维持数据一致性的难度。就像分库分表一样,它的痛,只有用过的人才知道,因此,往往只会作为终极优化手段。不用则已,用则需要有面对困难的勇气和决心。
作为一名程序员,你一定听过这样一句话:好的架构不是设计出来的,而是演化出来的。想要获得什么,就要付出代价,就像想要讨老婆,就得努力挣钱一样。优化会使代码逻辑变得复杂,流程变得混乱。因此简单设计,先上线,用钱堆,这些看起来很土的选择很多时候可能比盲目优化更能使我们远离漩涡。
但无论如何,经常的,持续的分煎饼是个好习惯。
特别是山东煎饼,山东泰安的。











