dubbo 开发一个线上系统时候遇到的内存泄漏生产问题的排查与优化实践经验

 分类:
分类: 已被围观
已被围观
今天给大家分享一个我们之前基于 dubbo 开发一个线上系统时候遇到的内存泄漏生产问题的排查与优化实践经验。
相信对于大家多看一些类似的案例,以后对于大家自己在线上系统遇到各种生产问题的时候,进行排查和优化的思路会有很大的启发。
事故背景
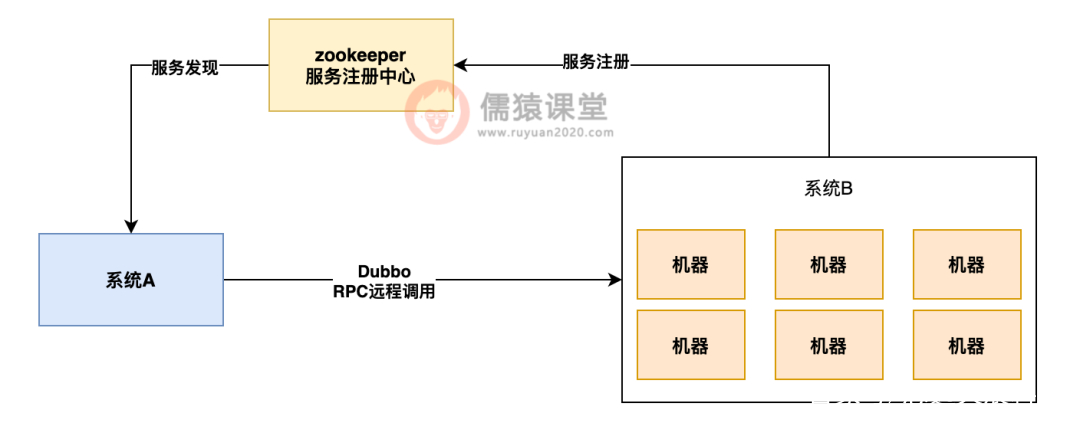
先给大家简单说一下这个问题的发生背景,线上生产环境部署了两个系统,我们可以认为是系统 A 和系统 B,同时系统 B 因为是大流量核心系统,所以部署了几十台机器,定位就是集群部署要抗每秒几万的 TPS 的,两台系统之间是基于 dubbo 作为 rpc 调用框架,注册中心用的是 zookeeper。
如下图所示:
 编辑搜图
编辑搜图
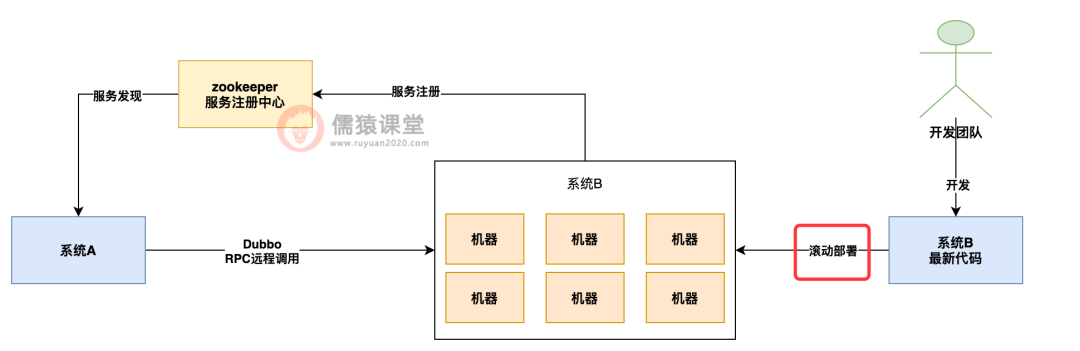
在这个背景之下,某一天系统 B 因为更新了代码,因此发起了一次几十台机器的全量滚动更新和部署。
也就是说,系统 B 的开发团队基于最新的代码把几十台机器依次用最新代码重新部署了一遍,也就是每台机器都会有一次系统停止和重启的过程。
如下图所示:
 编辑搜图
编辑搜图
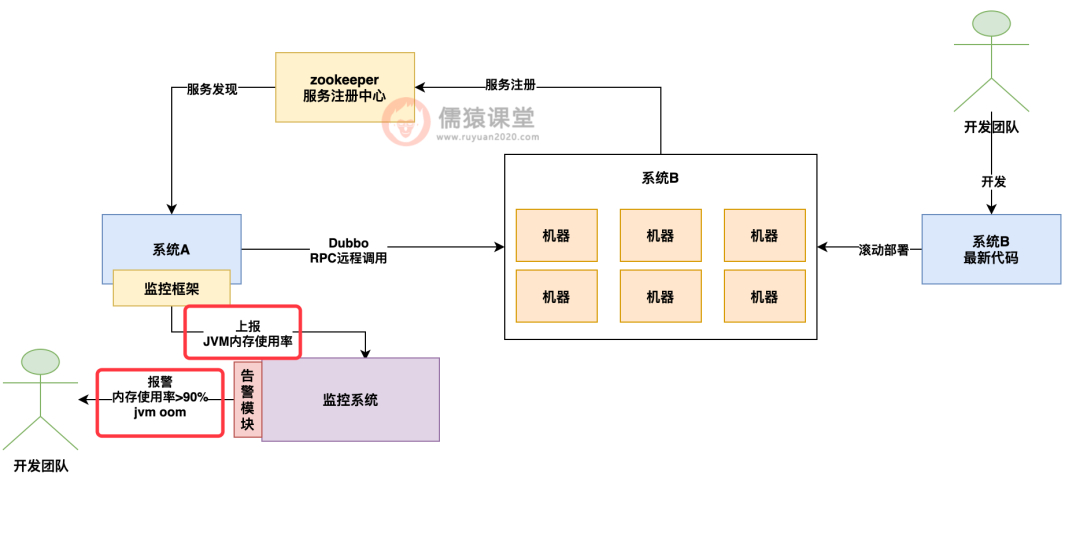
没想到生产环境的灾难性故障就这么突然发生了,在系统 B 的几十台机器依次重新部署之后,结果系统 A 的开发团队惊讶的发现自己的系统居然过了一会就发送了 jvm 内存使用率飙升超过 90% 的告警,而且很快系统 A 居然就直接 OOM 内存溢出崩溃了。
如下图所示:
 编辑搜图
编辑搜图
于是系统 B 的开发团队顺利的把一个大版本更新了几十台机器之后,心满意足的欣赏自己的成果呢,系统 A 的开发团队突然开始一脸懵逼的手忙脚乱进行了生产故障的排查。
那么大家可以想想,这个时候,如果是你负责的线上系统突然给你发送内存使用率飙升超过 90%,而且很快就 oom 内存溢出,你会怎么排查?
排查思路
这里给大家说说当时我们是怎么进行排查的,首先,遇到这种内存突然飙升然后导致 oom 的情况,先看看是不是外部对你的请求流量过大导致的。
因为往往这种突发性的问题,都是外部流量突然飙升导致的,这里先给分析一种外部流量突然飙升导致系统 oom 的场景。
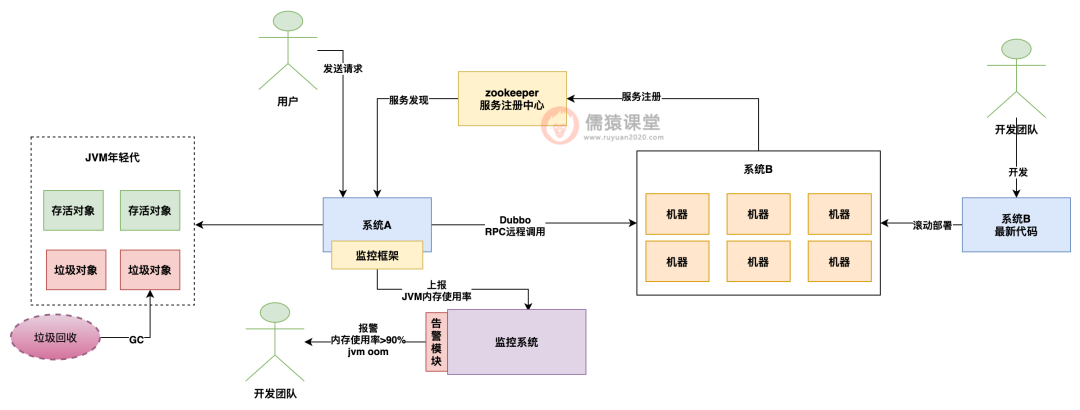
假设你平时常规化运作的时候,每次一批请求过来会在你的 jvm 年轻代里创建一批对象,接着这批请求处理完毕了,之前创建的那批对象就会成为垃圾对象了,然后下一批请求过来,又在 jvm 年轻代里创建了一批对象。
如下图所示:
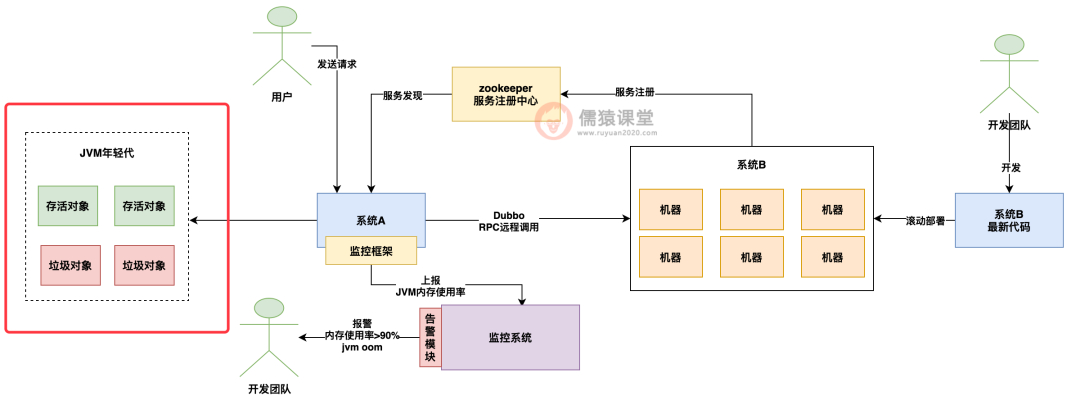 编辑搜图
编辑搜图
那么正常情况下,你的 jvm 年轻代里肯定对象会越来越多是不是?但是其实一般到了一定时候,年轻代里的存活对象基本很少,因为大部分的对象都是之前已经处理完毕的请求创建的对象,他们其实都是一些没用的垃圾对象。
所以其实正常情况下跑一段时间后,会触发一下 jvm 年轻代的垃圾回收,把垃圾对象都回收掉就行了。
如下图:
 编辑搜图
编辑搜图
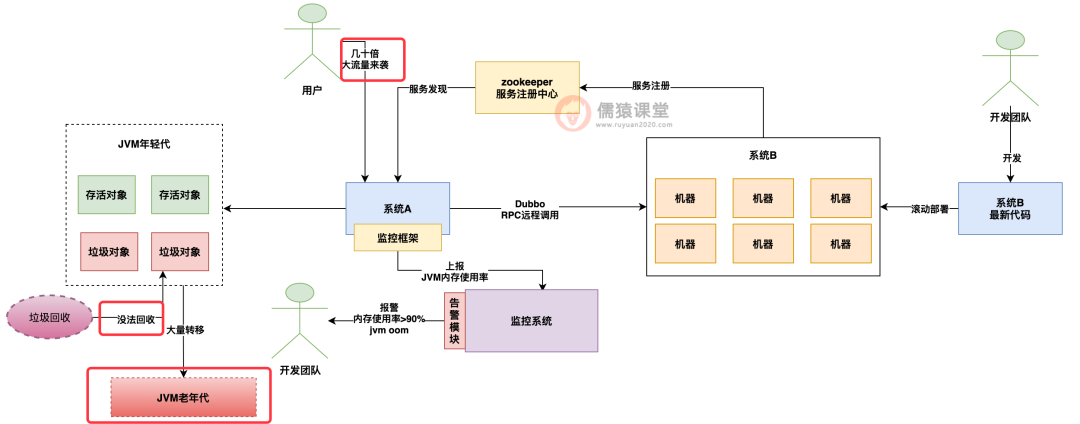
所以正常情况下,是不会出现什么问题的,但是如果是突发性的大流量来袭呢?
这个时候就不好说了,因为很可能在短时间内突然涌入大量的请求,这些请求创建了大量的对象,瞬间就填满了年轻代,然后这个时候触发年轻代 gc 后,发现大量的对象是没法回收的,此时只能怎么办?
只能把这些对象转移到老年代里去了,如下图:
 编辑搜图
编辑搜图
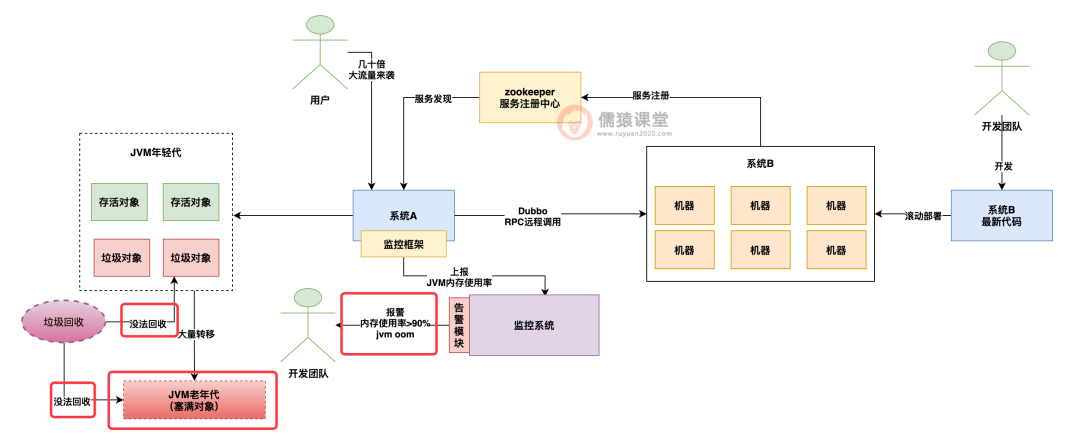
那么这个时候年轻代里的大量存活对象都转移到老年代里去了,老年代里几乎也被填满了,然后此时年轻代里因为流量太大瞬时再次被填满,此时年轻代里大量的存活对象该何去何从?这个时候你去老年代吗?
老年代都塞满了存活对象,即使触发了老年代 gc 也没法回收他们,年轻代也没地方放这些存活对象了,这个时候会如何?
很简单,由于瞬时并发流量太大,同时创建了太多的存活对象,塞满了老年代和年轻代,我们很可能会收到报警说 jvm 年轻代和老年代内存使用率都超过了 90%。
而且这些对象都是存活的都没法回收,此时再要创建新的对象,就没地方创建了,接着就会报出 oom 内存溢出异常来了。
如下图:
 编辑搜图
编辑搜图
所以说瞬时流量激增可能会导致系统 A 发送内存使用率超过 90%,而且很快就 oom 的问题,但是到底是不是这个问题导致的呢?
虽然我们可以思路顺畅的推演出上述场景,但是我们这个时候赶紧看一下系统 A 的线上 QPS 指标监控,结果一脸懵逼的发现,系统 A 根本就没有流量激增,人家的流量一切都很平稳,所以根本不是这个原因导致的问题。
那既然不是这个问题,那还有什么问题会导致这个现象呢?
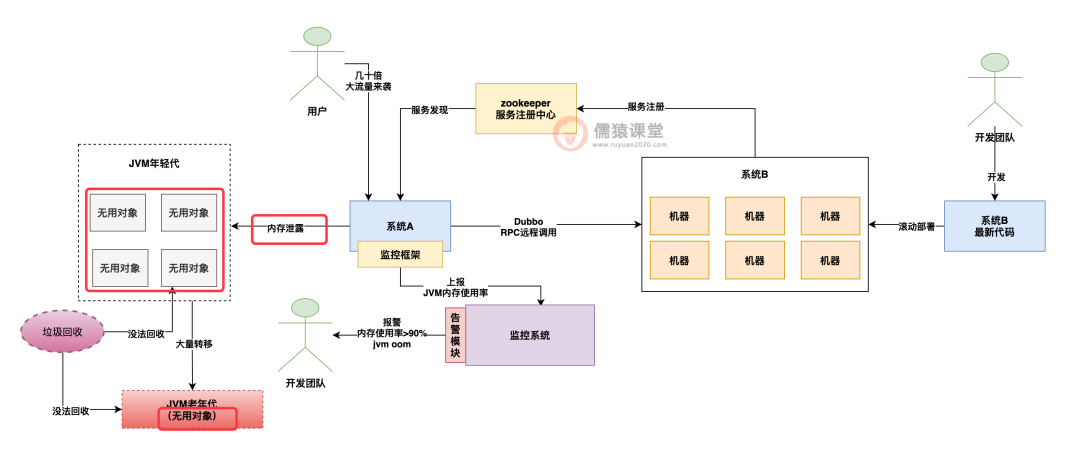
很简单,第二种问题就是内存泄漏,也就是说,在某种特殊条件下,触发了一个内存泄漏的行为,就是你的系统不停的产生某一类对象,这一类对象明明都不用了,结果还一直放在内存里,而且根本回收不掉。
就这么不停的积累这类对象,就会导致内存使用率不停的攀升,最后导致 oom 内存溢出。
如下图:
 编辑搜图
编辑搜图
那么针对这个内存泄漏的问题,这个时候我们到底应该怎么排查呢?很简单,这个时候你到底是真程序员还是假程序员,得亮亮真功夫了。
往往这种内存类的问题,过段的用 jmap 这个命令,去对线上运行的系统 jvm 进程生成一个内存 dump 快照出来,然后把 dump 快照下载到本地,用 MAT这个工具就可以分析这个内存快照。
在 MAT 工具中我们会看到你的 jvm 里到底是什么破对象占用了那么大的空间,才导致了你的内存使用率飙升到 90%+ 的。
这个时候其实导致内存泄漏的原因有很多种,比如说你们自己代码写的不好,就是每次请求都创建某一类对象,这类对象给扔到某个 class 的静态 map 里一直放着,从来不回收,也没法回收,导致这类无用对象一直增长,最后导致了 oom。
另外还有一种比较常见的现象,就是我们的系统使用了一些开源框架,这些开源框架在某种特殊场景下创建了一堆的对象,没法回收,他自己也从来不回收,导致了开源框架悄咪咪创建的这批对象占用了大量内存,导致了内存泄漏。
所以在这里给大家说一下我们当时遇到的一个问题,大家重点吸收排查思路,下面的具体 case by case 的个别案例可以作为一个例子看一下。
排查案例
就我们当时的 case 来说,经过 MAT 一通排查,发现占用了大量内存的对象是 dubbo 框架创建的,dubbo 框架创建了一种用于进行 rpc 调用的大对象,这类对象一直创建一直增长,然后从来不回收,最后导致了内存泄漏和内存溢出。
如下图:
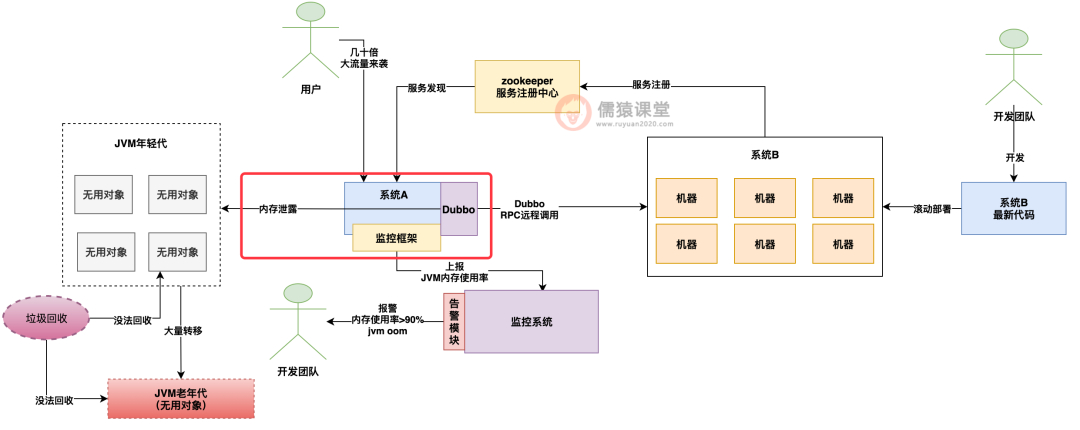 编辑搜图
编辑搜图
那么 dubbo 框架为什么会不停的创建一类用于进行 rpc 调用的对象呢?
这就得分析 dubbo 框架的源码了,当时经过 dubbo 框架源码的分析,我们得出了以下的问题发生流程:
当系统 B 在线上进行几十台机器的滚动发布的时候,每一台机器被发布,都会导致注册中心感知到服务变动,然后注册中心会把这几十台机器的地址列表都给系统 A 推送过去。
也就是说,连续发布几十台机器,就会导致注册中心推送几十次最新地址列表,每一次推送都包含了几十台机器的地址。
因此,假设系统 B 部署了 50 台机器,等于随着 50 台机器依次重新发布,会导致注册中心一共给系统 A 推送 50*50=2500 条机器地址。
如下图:
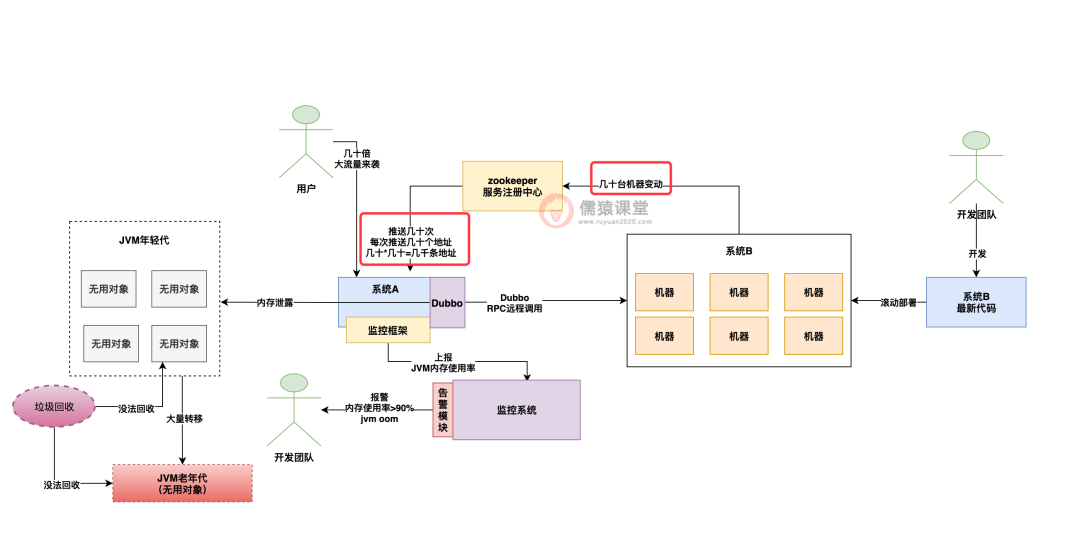 编辑搜图
编辑搜图
而系统 A 的 dubbo 框架等于会收到短时间内频繁推送的几千条机器地址,然后对每条机器地址,其实 dubbo 框架都会去创建一个对应的 rpc 调用类的对象。
如下图所示:
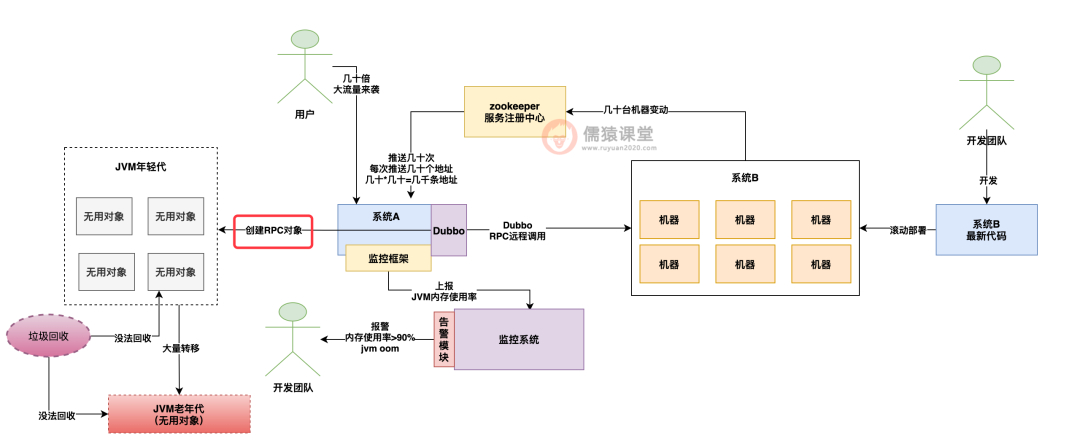 编辑搜图
编辑搜图
其实本来 dubbo 创建几千次 rpc 调用对象也没什么,但是问题就出在了一个特殊的 case 上了。
那就是系统 B 那边并没有去设置对外提供的是什么 rpc 协议,因为 dubbo 是支持多种不同的 rpc 协议的,比如说 dubbo 协议、http 协议,等等。
所以在当时的那个较老的 dubbo 版本中,就出现了一个隐藏的问题,就是如果系统 B 没设置具体对外提供的协议版本,就会导致系统 A 收到几千条机器地址后,除了创建 dubbo 协议的对象,还会创建几千个基于 http rest 类协议的 rpc 调用对象。
可是系统 B 又没提供 http rest 接口,因此创建会全部失败,但是背后创建的大量对象又会放着,没法回收。
这就导致了 dubbo 框架不停的创建出来大量的对象,占用了 90% 的内存,最后导致了内存溢出。
如下图:
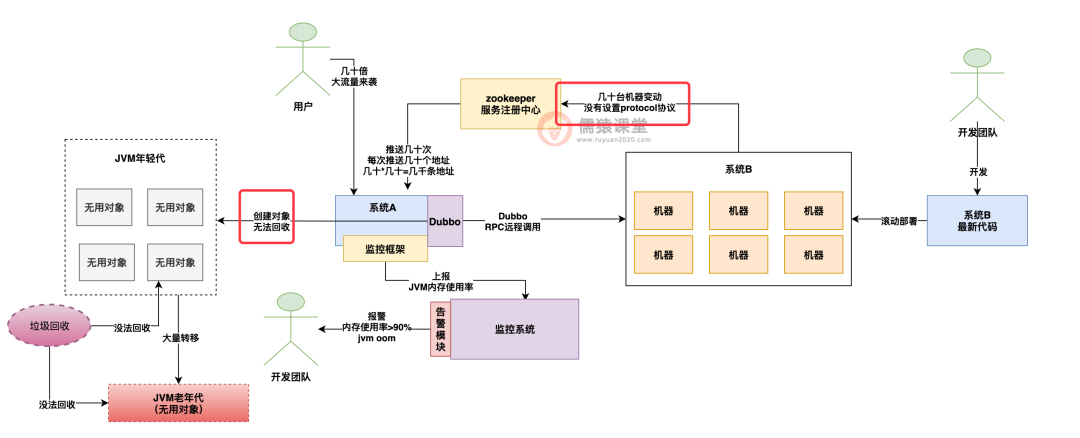 编辑搜图
编辑搜图
那么这个问题是如何解决的呢?其实问题的核心在于排查思路和背后的原理,最后问题的解决往往是 case by case 的。
比如我们这个case里,其实就很简单,就是要让系统 B 设置好对外提供的 dubbo protocol 协议,避免上面那种因为 protocol 协议没设置导致创建了大量的无用对象没法回收。
总结
最后希望大家看完今天的生产排查与优化案例后,未来在自己工作中遇到了类似的问题,能给大家提供一种问题排查的思路帮助大家。












我有话说: