如何将阿里云EMR中的Hive表数据迁移为Iceberg表?

 分类:
分类: 已被围观
已被围观
背景
某客户现在有大量Hive表存放在阿里云EMR集群之上,考虑到Iceberg在ACID、变更、近实时等方面做的更好(把Hive表迁移成Iceberg表的收益,参考文章 从Hive表切换到Iceberg表的收益探讨 https://www.yuque.com/huzijin-og9kx/gywdy7/hafnp9 ) 。
客户想把他们的Hive表迁移到阿里云EMR的Iceberg表。那么,此时应该如何操作呢?
操作流程
限制:
-
目前只支持将Parquet/Avro/Orc三种文件格式的Hive表迁移成Iceberg表;
-
建议采用EMR-5.5.0及以上版本,因为spark和iceberg的集成都相对完善。
注意:以下流程适用于选择HiveMetastore元数据的阿里云EMR集群。
第一步 创建Hive原始数据
创建一个测试用的Hive表来验证我们的迁移流程。(如下语句在spark-sql中执行)
-- 创建 hive_src 表CREATE TABLE IF NOT EXISTS hive_src ( id INT, data STRING) STORED AS parquet LOCATION 'oss://emr-iceberg/migration/hive_src'; -- 写入 4 条测试数据INSERT INTO hive_src VALUES (1, 'AAA'), (2, 'BBB'), (3, 'CCC'), (4, 'DDD');-- 复制数次测试数据INSERT INTO hive_src SELECT * FROM hive_src;INSERT INTO hive_src SELECT * FROM hive_src;INSERT INTO hive_src SELECT * FROM hive_src;INSERT INTO hive_src SELECT * FROM hive_src;
在迁移到Iceberg操作完成之前,我们查看这个Hive表的元数据信息如下:
hive> desc formatted hive_src;OK# col_name data_type comment
id int data string
# Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Tue Mar 01 16:16:52 CST 2022 LastAccessTime: UNKNOWN Retention: 0 Location: oss://emr-iceberg/migration/hive_src
Table Type: EXTERNAL_TABLE
Table Parameters: EXTERNAL TRUE numFiles 16 spark.sql.create.version 3.2.0 spark.sql.sources.schema {\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"data\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]} totalSize 12046 transient_lastDdlTime 1646122742 # Storage Information SerDe Library: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe InputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat OutputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat Compressed: No Num Buckets: -1 Bucket Columns: [] Sort Columns: [] Storage Desc Params: serialization.format 1 Time taken: 0.042 seconds, Fetched: 31 row(s)
可以看到,这个表是一个Hive表,而不是Iceberg表。
第二步 启动spark-sql命令行
打开加载iceberg extensions插件的spark-sql命令行如下:
spark-sql --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \ --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \ --conf spark.sql.catalog.spark_catalog.type=hive \ --conf spark.sql.catalog.hive=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.hive.type=hive \ --conf spark.sql.catalog.hive.uri=thrift://emr-header-1.cluster-286818:9083 \ --conf spark.sql.catalog.hive.warehouse=oss://emr-iceberg/migration/iceberg_dst
其中 spark.sql.catalog.hive.uri 的值(对应HiveMetastore的thrift server地址)通过如下方式获取:
[root@emr-header-1 ~]# cat $HIVE_CONF_DIR/hive-site.xml | grep metastore.uri -1 <property> <name>hive.metastore.uris</name> <value>thrift://emr-header-1.cluster-286818:9083</value>
第三步 执行Hive表迁移到Iceberg的操作
spark-sql> CALL hive.system.migrate('spark_catalog.default.hive_src');16Time taken: 1.769 seconds, Fetched 1 row(s)
在执行完这个迁移命令之后,再次打开Hive的命令行,可以查看hive_src表的元数据信息如下:
desc formatted hive_src ; OK# col_name data_type comment
id int data string
# Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Tue Mar 01 16:20:18 CST 2022 LastAccessTime: Wed Jan 14 15:32:23 CST 1970 Retention: 2147483647 Location: oss://emr-iceberg/migration/hive_src
Table Type: EXTERNAL_TABLE
Table Parameters: EXTERNAL TRUE metadata_location oss://emr-iceberg/migration/hive_src/metadata/00000-d82097f0-790d-4dad-935c-9d8482c848f9.metadata.json migrated true numFiles 16 numRows 512 schema.name-mapping.default [ { \"field-id\" : 1, \"names\" : [ \"id\" ] }, { \"field-id\" : 2, \"names\" : [ \"data\" ] } ] table_type ICEBERG totalSize 12046 transient_lastDdlTime 1646122818 # Storage Information SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe InputFormat: org.apache.hadoop.mapred.FileInputFormat OutputFormat: org.apache.hadoop.mapred.FileOutputFormat Compressed: No Num Buckets: 0 Bucket Columns: [] Sort Columns: [] Time taken: 0.051 seconds, Fetched: 38 row(s)
这里可以明显地看出,里面有一个字段 table_type=ICEBERG 表明这个表是一个Iceberg。另外,我们查看Iceberg对应的OSS目录如下:
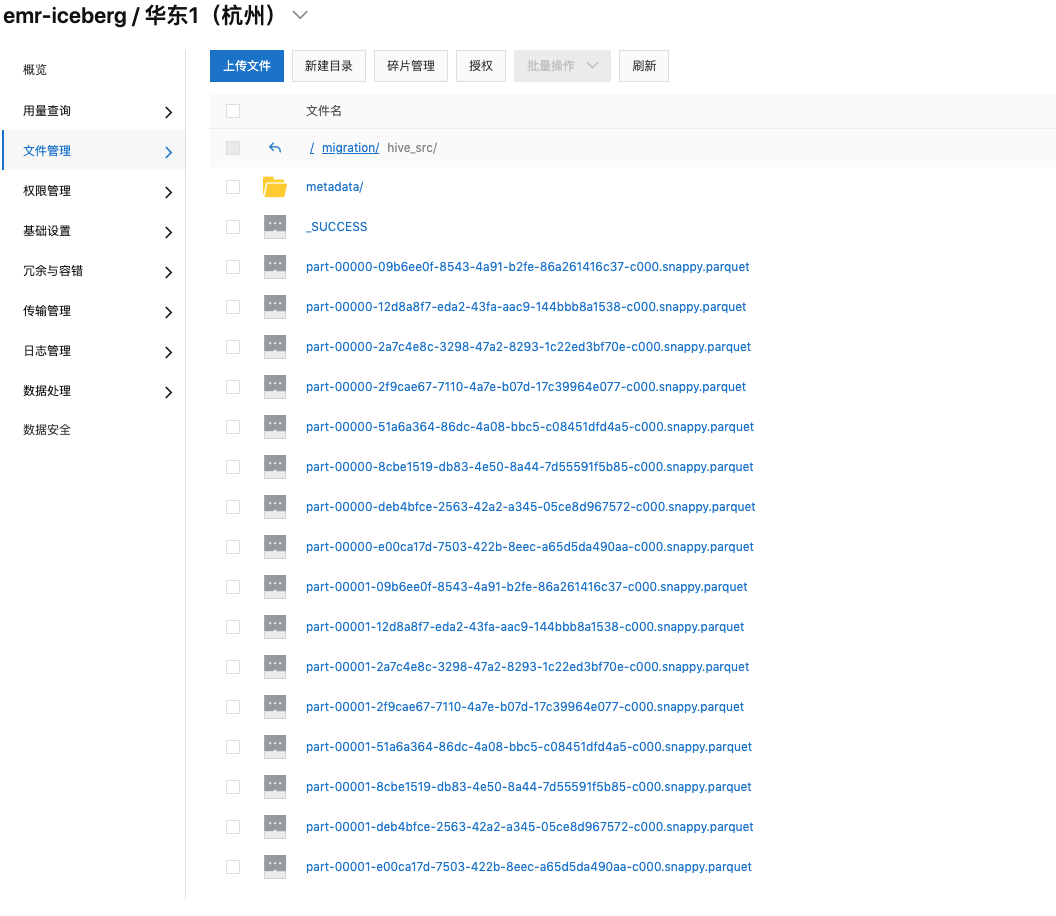
第四步:用Hive表方式和Iceberg表方式分别查询这个表。
首先,我们采用Hive表的方式来查询这个表:
spark-sql> select * from hive.default.hive_src limit 3;1 AAA2 BBB3 CCCTime taken: 0.319 seconds, Fetched 3 row(s)
可以看出,虽然这个表已经为iceberg表重新生成了metadata,但是该表依然可以通过原先的hive方式来查询。
然后,我们采用Iceberg表的方式来查询这个表:
spark-sql> select * from spark_catalog.default.hive_src limit 3;1 AAA2 BBB3 CCCTime taken: 0.427 seconds, Fetched 3 row(s)
总结
目前在阿里云EMR集群上,可以非常方便地将hive表切换成iceberg表,只需要执行一条命令即可。而且即使一个Hive表有数十PB,整个迁移过程也是非常快速的,因为本质上Hive表迁移到Iceberg表只需要重新为Iceberg表生成一遍metadata即可,不需要做任何实质上的数据文件迁移。












我有话说: