Apr
02
2021
Web应用防火墙提供的防护功能拦截恶意爬虫的最佳实践

 分类:
分类: 已被围观
已被围观

本文介绍了使用Web应用防火墙提供的防护功能拦截恶意爬虫的最佳实践。
背景信息
当今互联网爬虫种类繁多,且为了绕过网站管理员的防爬策略,专业的爬虫往往会不断变换爬取手段。因此,依靠固定的规则来实现一劳永逸的完美防护是不太可能的。此外,爬虫风险管理往往与业务自身的特性有很强的关联性,需要专业的安全团队进行对抗才能取得较好的效果。
如果您对防爬效果有较高的要求,或者缺乏专业的安全团队来配置相应的安全策略,您可以使用Web应用防火墙Bot管理模块提供的爬虫防护功能。Bot管理模块基于阿里云对全网威胁情报实时计算得到的恶意爬虫IP情报库、动态更新的各大公有云、IDC机房IP库等情报信息,可以帮助您直接放行合法爬虫请求,并对来自威胁情报库的恶意请求进行防护处置。
说明 Bot管理模块属于增值服务,需要在购买或升级Web应用防火墙时单独开通。
除了Bot管理模块,您还可以参照下文介绍的爬虫请求的特征,结合Web应用防火墙的自定义防护策略、IP黑名单功能设置针对性的爬虫拦截规则。
恶意爬虫的危害和特征
正常爬虫请求的user-agent字段中通常包含xxspider标识,并且爬取的请求量不大,爬取的URL和时间段都比较分散。如果对合法的爬虫IP执行反向nslookup或tracert,一般都可以看到爬虫的来源地址。例如,对百度的爬虫IP执行反向nslookup,即可查询到其来源地址信息。
恶意爬虫则可能会在某个时间段大量请求某个域名的特定地址或接口,这种情况很可能是伪装成爬虫的CC攻击,或是经第三方伪装后针对性爬取敏感信息的请求。当恶意爬虫请求量大到一定程度后,往往造成服务器的CPU飙升,带来网站无法访问等业务中断问题。
设置自定义防护策略
通过设置WAF自定义防护策略,您可以灵活地结合User-Agent和URL等关键字段来过滤恶意爬虫请求。
配置示例:
-
您可以在控制台的自定义防护策略页面配置以下ACL访问控制规则,只放行百度爬虫,而过滤其他的爬虫请求。
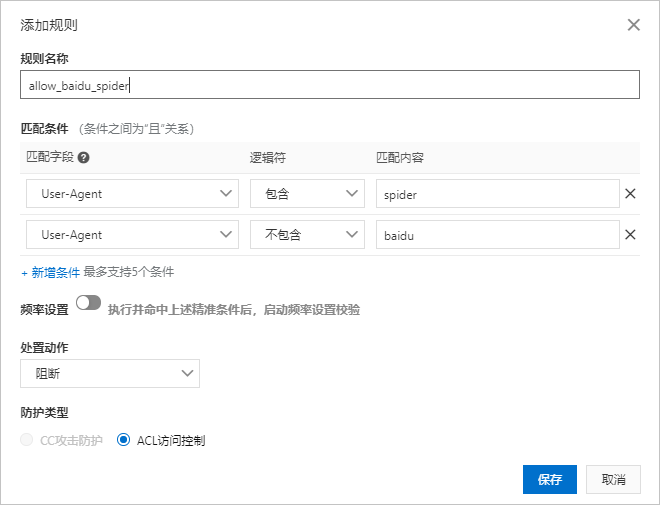
-
您可以在控制台的自定义防护策略页面配置以下ACL访问控制规则,禁止任何爬虫访问/userinfo目录下的内容。
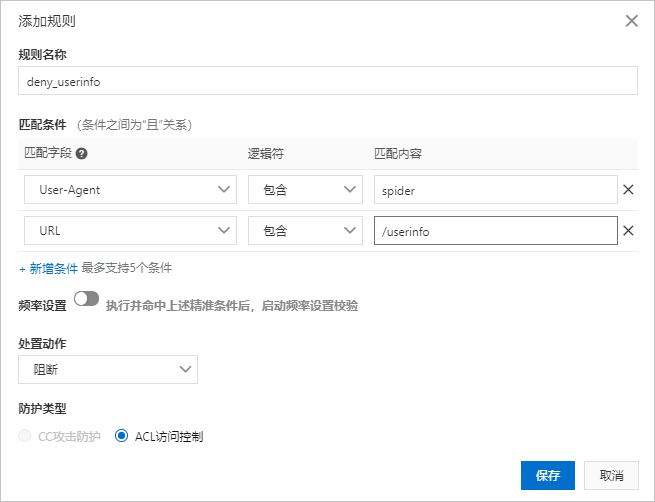
说明 通过限制User-Agent字段的方式在面对恶意攻击者精心构造的爬虫攻击时很容易被绕过。例如,恶意攻击者可以通过在恶意爬虫请求的User-Agent字段中带有baidu字符,伪装成百度爬虫而不被该ACL访问控制规则拦截。甚至,恶意攻击者可以通过在User-Agent字段中去除spider字符,隐藏爬虫身份,则该ACL访问控制规则将无法拦截。
如果您发现恶意爬虫请求具有高频的特征,您还可以使用自定义防护策略的频率设置,针对特定的路径配置基于IP的访问频率的检测和阻断规则。
配置示例:您可以在控制台的自定义防护策略页面配置以下规则,当一个IP在30秒内访问当前域名下任意路径的次数超过1000次,则封禁该IP的请求10个小时。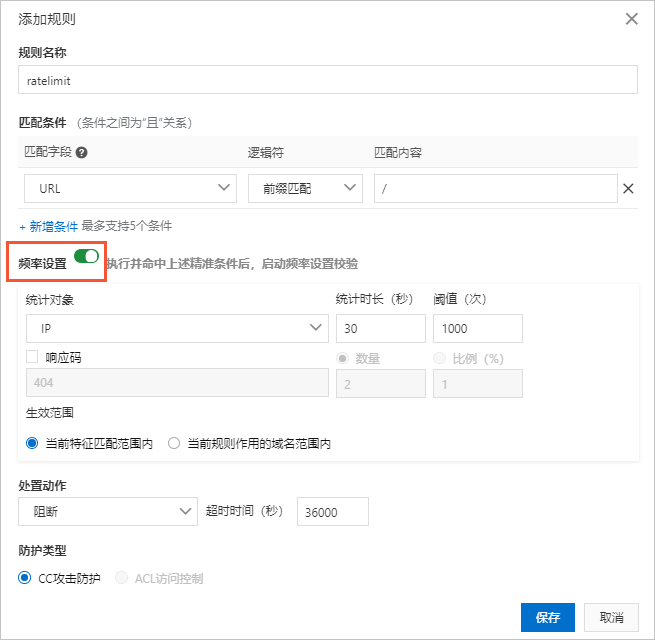
如果您开通了旗舰版的Web应用防火墙实例,则您可以在频率设置中使用除IP和Session外的自定义统计对象字段,设置更细粒度、更多维度的限速功能。例如,由于针对IP的封禁会影响NAT出口,您可以使用cookie或者业务中自带的用户级别参数作为统计对象。下图配置针对业务中标记用户的cookie(假设cookie格式为uid=12345)进行统计,并使用滑块作为处置动作,避免误拦截。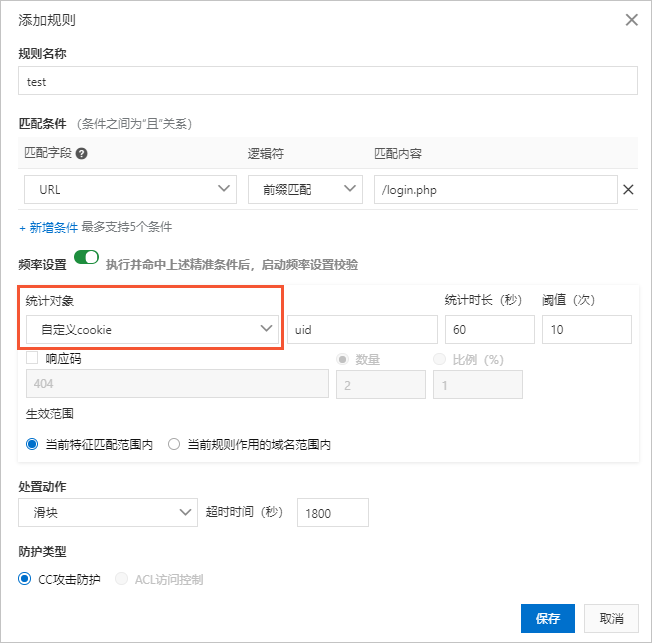
设置IP黑名单
如果您发现有大量恶意爬虫请求来自于特定区域,且正常的业务访问都没有来自该区域的请求,则可以开启地域级IP黑名单,直接拦截该特定区域的所有访问请求。
配置示例:您可以在控制台的IP黑名单页面配置以下规则,封禁中国境外IP地址的访问请求。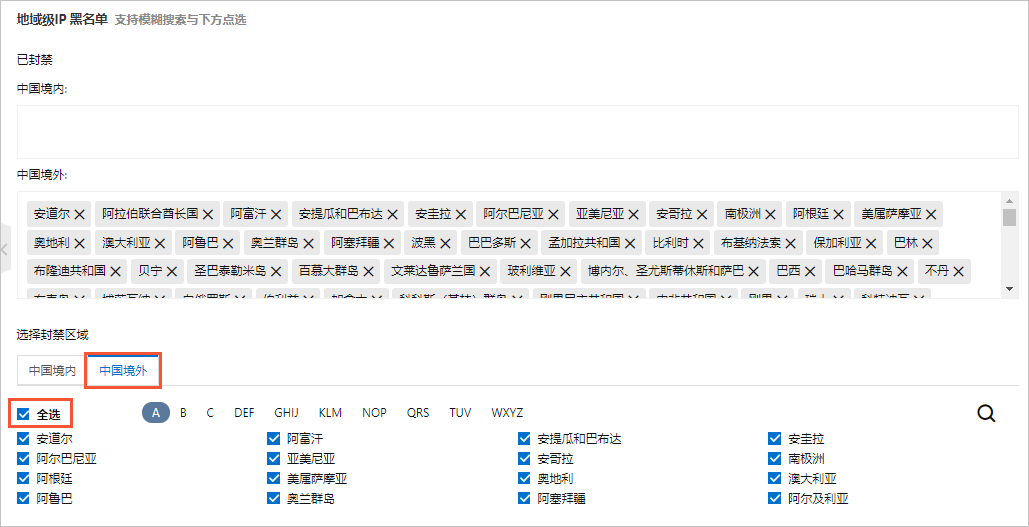
我公司为阿里云代理商,通过此页面下单购买,新老阿里云会员,均可享受我公司代理商价格!![]()
本公司销售:阿里云新/老客户,只要购买阿里云,即可享受折上折优惠!>












我有话说: