云原生混部最后一道防线:节点水位线设计

 分类:
分类: 已被围观
已被围观 1.引言
在阿里集团,在离线混部技术从 2014 年开始,经历了七年的双十一检验,内部已经大规模落地推广,每年为阿里集团节省数十亿的资源成本,整体资源利用率达到 70% 左右,达到业界领先。这两年,我们开始把集团内的混部技术通过产品化的方式输出给业界,通过插件化的方式无缝安装在标准原生的k8s集群上,配合混部管控和运维能力,提升集群的资源利用率和产品的综合用户体验。
由于混部是一个复杂的技术及运维体系,包括 K8s 调度、OS 隔离、可观测性等等各种技术,之前的 2 篇文章:历经 7 年双 11 实战,阿里巴巴是如何定义云原生混部调度优先级及服务质量的?如何在云原生混部场景下利用资源配额高效分配集群资源?今天我们要关注的是混部在单机运行时的最后一道防线——单机水位线设计。
2.为什么需要单机水位线

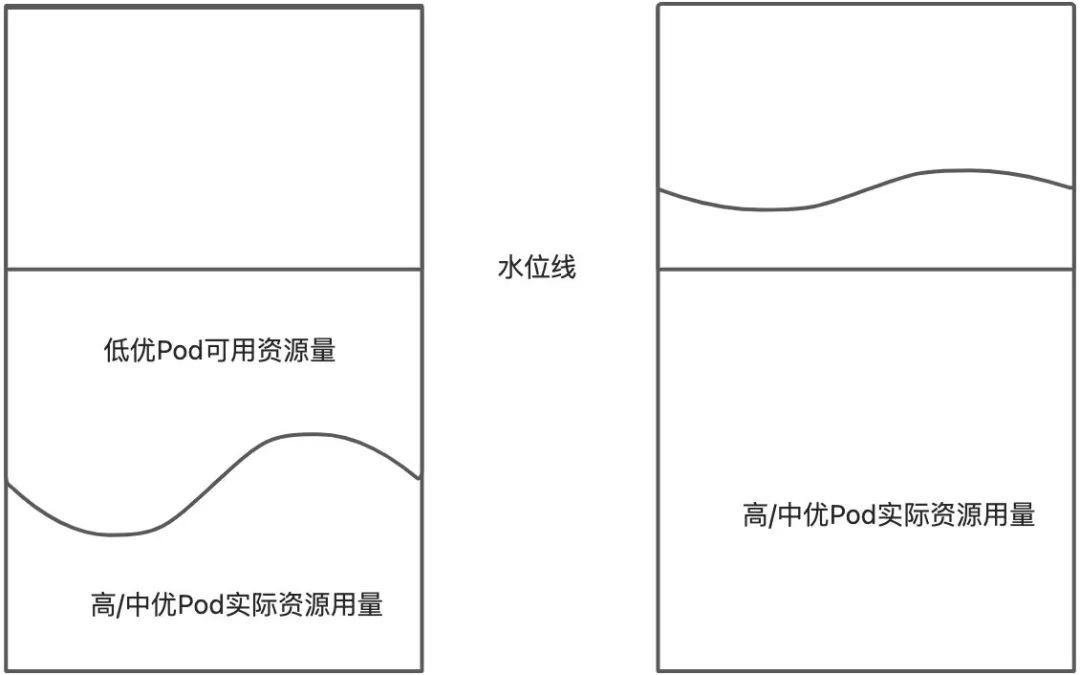
如上图所示,Pod 的运行时的三个生命周期阶段,在经过配额检查和调度后,终于,不同 Qos 等级的 Pod 运行在同一个节点上了,这个时候,高优和中优的 Pod 使用的是节点上的容器分配总量,而低优 Pod,则是基于高中优实际的资源用量,然后被调度器调度到节点上面去运行。从下图可以看到,当一个节点上还有较多的空余资源时,完全可以提供给低优资源使用,而当高/中优 Pod 实际资源用量高过一定的值之后,资源竞争非常激烈时,节点上再跑低优 Pod 只会导致高/中优 Pod 的服务质量受损,所以这个时候,我们将不再允许低优 Pod 在这个节点上运行。为了标识或者说判断节点资源的竞争激烈程度,那么非常顺理成章的一个设计就是,看这个节点上的资源使用率是否过高。如果超过一定使用率,那么我们就需要对低优 Pod 做相应的操作。这个判断的临界阈值,就是单机的水位线。
 编辑搜图
编辑搜图
这里另外能看到的一点是,水位线仅仅是为低优 Pod 所设置的,高/中优 Pod 并不会感知到水位线,他们可以自由地使用整机的所有资源,所有的系统行为都和没有打开混部是一样的。
3.水位线的分级
对于一个资源趋向于饱和的节点来说,我们对于低优 Pod 可以有各种操作的手段,如果仅仅是简单的杀掉低优 Pod 的话,整个混部系统也可以工作,这个动作我们称为“驱逐”。但如果在一定时间后,机器上的资源竞争又降低的话,那么低优 Pod 被杀死并在别的机器上重新启动,这里会大大延长低优 Pod 的单个任务的执行时间,所以在设计单机水位线时,需要尽可能的让低优 Pod 也要在可以允许的时间范围内能够“降级”运行。所以,我们有对低优 Pod 的第 2 种操作,就是降低对它的 CPU 供给量,这个操作我们称为“压制”。同时,如果一个节点上的资源趋于饱和,另外还比较顺理成章的系统行为就是不让新的低优 Pod 被调度进来。
于是我们对于节点上低优 Pod 的行为就有 3 种:压制、驱逐和禁止调度,由此就有三条水位线,同时,对于 CPU 这类的可压缩资源和内存这类不可压缩资源,行为还有区别。
注:可压缩资源(例如 CPU 循环,disk I/O 带宽)都是速率性的可以被回收的,对于一个 task 可以降低这些资源的量而不去杀掉 task;和不可压缩资源(例如内存、硬盘空间)这些一般来说不杀掉 task 就没法回收的。来自文章《在 Google 使用 Borg 进行大规模集群的管理 5-6》- 6.2 性能隔离[1]
这些水位线总体列表如下:
|
水位线 |
系统行为 |
CPU |
内存 |
|
禁止调度水位线 |
不让新的低优 Pod 被调度到这个节点上 |
有 |
有 |
|
压制水位线 |
压制低优 Pod 的资源用量 |
有 |
无 |
|
驱逐水位线 |
在这个节点上杀死低优 Pod,让上层应用重新拉起新 Pod 进入重调度流程,看是否能运行在别的节点上 |
有 |
有 |
这些水位线的合理配置值,应该是 驱逐>压制>禁止调度。不过在实际的混部生产中,我们一般会把禁止调度水位线和压制水位线使用同一个配置值,来降低系统运维同学的理解成本,以及配置工作量。这样合并后就会存在 CPU 的 2 条水位线,内存的一条水位线。
4.驱逐条件:基于满足度的驱逐模式
 编辑搜图
编辑搜图
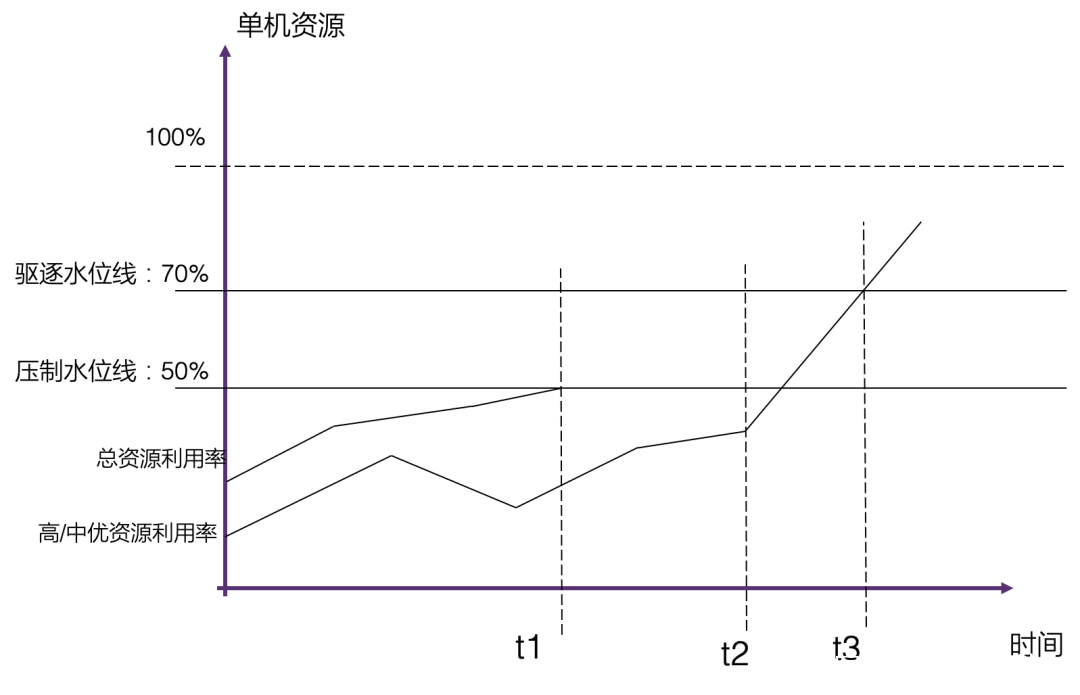
这张图展示了单机上实际的系统运行例子:
-
在 t1 时间,总资源利用率达到压制水位线的时候,对低优先级的任务进行压制,保证整体资源利用率在压制水位线之下,此时低优任务不会再被调度进来
-
在 t3 时间,总资源利用率开始进一步上升,达到驱逐水位线时,会对低优任务进行删除和驱逐的处理,保证高/中优的资源使用
一个容易考虑到的设计是,驱逐低优任务前去设定一个延迟时间,这样可以让低优 Pod 有更多的机会等到系统有足够的资源,继续运行,然而这个设计,会造成几个问题:
-
内存的驱逐必须是实时的,因为节点上内存不足,会导致高/中优任务内存不足而 OOM
-
这个延迟时间并不好配置,配的短了没有效果,配了长了反而会引起低优 Pod 长期“饥饿”而造成低优 Pod 运行时间更长
-
如果在一个节点上,有多个低优 Pod 都在运行,是否要驱逐所有的低优 Pod?是否可能尽量的少驱逐 Pod?
因此,我们发明了基于满足度的低优 Pod 的 CPU 资源驱逐方式,定义了以下几个概念:
-
窗口期:获取 CPU 利用率的时间窗口(例如 5 分钟),在窗口时间的平均 CPU 利用率超过驱逐水位线,则开始驱逐,可以避免抖动
-
低优 Pod 资源满足率:= 低优 Pod 实际资源使用量/低优 Pod Request 资源量
-
低优 Pod 满足率下限:一个百分比值,低于这个值的认为低优 Pod 的资源供给不足
这样,低优 Pod 的驱逐条件就变为了:
-
窗口期内:平均低优 Pod 资源满足率 < 低优 Pod 满足率下限
-
窗口期内:低优 Pod 平均 CPU 利用率接近 100%(如 90% 或者 80%)
-
当前时间:平均低优 Pod 资源满足率 < 低优 Pod 满足率下限
-
最近时间:BE CPU 利用率接近100%(如 90% 或者 80%)
而驱逐低优 Pod 的排序为:
-
优先驱逐调度优先级 Priority 低的 Pod(是的,即使是低优 Pod,我们还是可以按照数值来细分不同的调度优先级)
-
如果 2 个 Pod 调度优先级一致,则计算驱逐哪一个 Pod 带来的资源释放更多,优先驱逐能释放更多资源的
内存的驱逐方式和 CPU 基本类似,但没有满足率,到了驱逐水位线按照优先级和内存大小来进行驱逐。
注:低优 Pod 的在别的节点上重建,还是依赖于低优 Pod 的管控系统(例如,离线计算的框架 Spark/Flink 等),这个重建过程往往涉及到临时缓存的文件或者数据的迁移和一致性的校验,这个重建操作并不适合在 K8s 层主动的去做操作,而是交给上层管控系统或者 operator 更加合适。
5.展望:是否有更好的设计?
在本文的开始,提到了衡量系统资源的竞争激烈程度,最简单和直观的就是看资源利用率。当然,在实际的大规模集群运行过程中,我们也看到了资源利用率高和资源竞争激烈并不是完全的一一对应关系,甚至有些应用在 CPU 利用率非常高的情况下,依然稳定运行,而另外一些应用,在一个低的 CPU 利用情况下,就会非常的“卡”。这就意味着如果我们有新的、更好的指标来衡量系统的利用率,那么我们对相应的 Workload 就能有更“微操”的操作,在保证应用 SLO 的同时,提升集群的资源利用率。
6.相关解决方案介绍
进入了 2022 年,混部在阿里内部已经成为了一个非常成熟的技术,为阿里每年节省数十亿的成本,是阿里数据中心的基本能力。而阿里云也把这些成熟的技术经过两年的时间,沉淀成为混部产品,开始服务于各行各业。云原生混部相关能力已经申请了多项独立的知识产权。
在阿里云的产品族里面,我们会把混部的能力通过 ACK 敏捷版,以及 CNStack(CloudNative Stack)产品家族,对外进行透出,并结合龙蜥操作系统(OpenAnolis),形成完整的云原生数据中心混部的一体化解决方案,输出给我们的客户。












我有话说: